
I’m a Ph.D. student in Computer Science at Virginia Tech, advised by Tu Vu. My research interests focus on transferring alignment-induced behaviors (SFT, RL) across models. My goal is to build modular, reusable systems where capabilities accumulate over time instead of being isolated in one-off training runs.
Efficient model development: Developing methods for faster, cheaper, and more reusable alignment updates, enabling continual adaptation across models.
Continually evolving agents: Building LLM agents that accumulate skills and raw experience for solving long-horizon tasks.
Parameter-efficient transfer learning: Modular task and document knowledge for scalable transfer.
Data-centric methods: Data selection and sampling strategies for stronger performance under limited compute or data.
Before starting my Ph.D., I completed my Master’s at Saarland University where I worked on efficient transfer learning and low-resource NLP with Dietrich Klakow and Vera Demberg. I was selected as a Google CSRMP Fellow in 2023, and most recently interned at Amazon AGI on distributed model distillation in 2025.
Seeking a Research Internship (Summer 2026). Interests: LLM post-training, agents, RL, deep reasoning, and efficiency. My CV is here.
🔥 News
- 2025.08: One paper accepted as an oral presentation at EMNLP 2025.
- 2024.10: One paper accepted to EMNLP 2024 Industry Track.
- 2024.09: Paper Target-Aware Language Modeling via Granular Data Sampling accepted to EMNLP 2024.
- 2024.08: Started my Ph.D. at Virginia Tech.
- 2024.07: Paper Exploring the Effectiveness and Consistency of Task Selection in Intermediate-Task Transfer Learning accepted to ACL 2024 SRW.
- 2024.02: Successfully defended my Master’s thesis Exploring Task Selection for Intermediate-Task Transfer Learning.
- 2024.02: Paper Modeling Orthographic Variation Improves NLP Performance for Nigerian Pidgin accepted to LREC-COLING 2024.
- 2024.01: Paper Projecting Annotations for Discourse Relations accepted to CODI @ EACL 2024.
📝 Selected Publications
Please see Google Scholar for an up-to-date publication list.
* indicates equal contributions
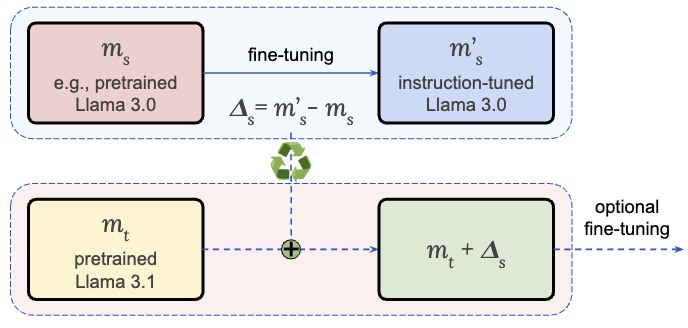
Pin-Jie Lin, Rishab Balasubramanian, Fengyuan Liu, Nikhil Kandpal, Tu Vu
EMNLP 2025 (Oral, top 10%)
[Paper] [Code]
Transferring alignment-induced capabilities (SFT, RL) across LLMs without re-training LLMs from scratch.
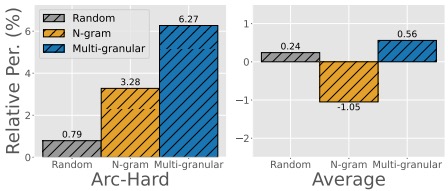
Ernie Chang, Pin-Jie Lin, Yang Li, Changsheng Zhao, Daeil Kim, Rastislav Rabatin, Zechun Liu, Yangyang Shi, Vikas Chandra
EMNLP 2024
[Paper]
Data-efficient pretraining: ~1% of RefinedWeb to match full pretraining performance.
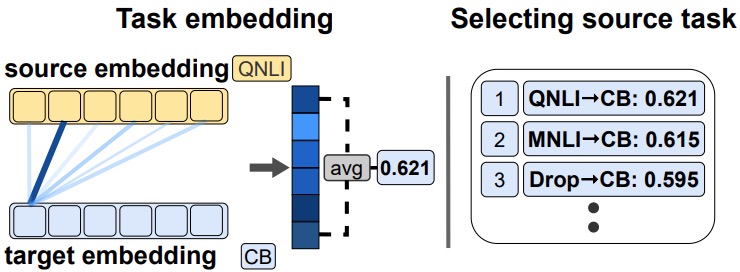
Pin-Jie Lin, Miaoran Zhang, Marius Mosbach, Dietrich Klakow
Student Research Workshop at ACL 2024
[Paper] [Code]
Robust modular task selection via point-wise similarity for transfer learning.
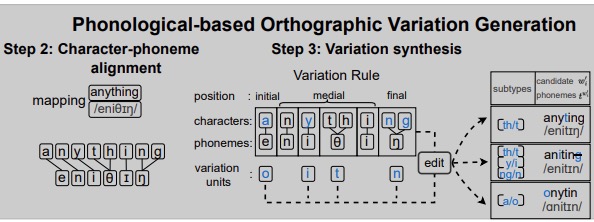
Pin-Jie Lin, Merel Scholman, Muhammed Saeed, Vera Demberg
LREC-COLING 2024
[Paper]
Generating synthetic data from a phonological-theoretic, parameter-free framework.
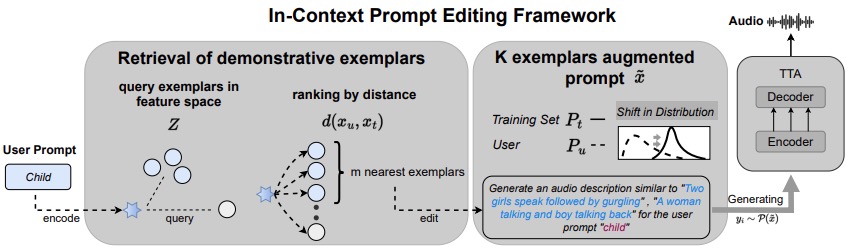
Ernie Chang*, Pin-Jie Lin*, Yang Li, Sidd Srinivasan, Gael Le Lan, David Kant, Yangyang Shi, Forrest Iandola, Vikas Chandra
ICASSP 2024
[Paper]
In-context control for conditional generation (GenAI); featured in HuggingFace Daily Paper.
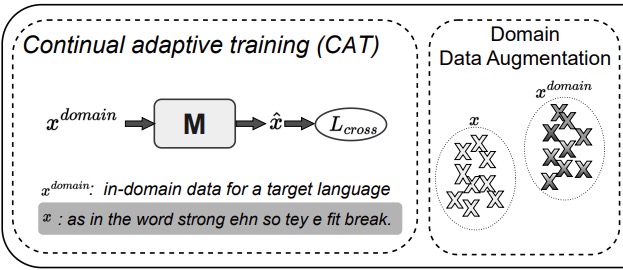
Pin-Jie Lin*, Muhammed Saeed*, Ernie Chang*, Merel Scholman
Interspeech 2023
[Paper]
Improving low-resource performance through mixed-language adaptation.
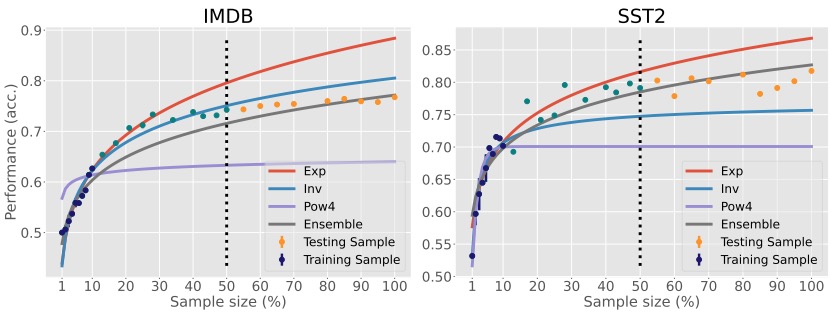
Ernie Chang*, Muhammad Hassan Rashid*, Pin-Jie Lin*, Changsheng Zhao, Vera Demberg, Yangyang Shi, Vikas Chandra
ACL 2023 Findings
[Paper] [Code]
Sample-size estimation for data-efficient NLU and more reliable scaling decisions.
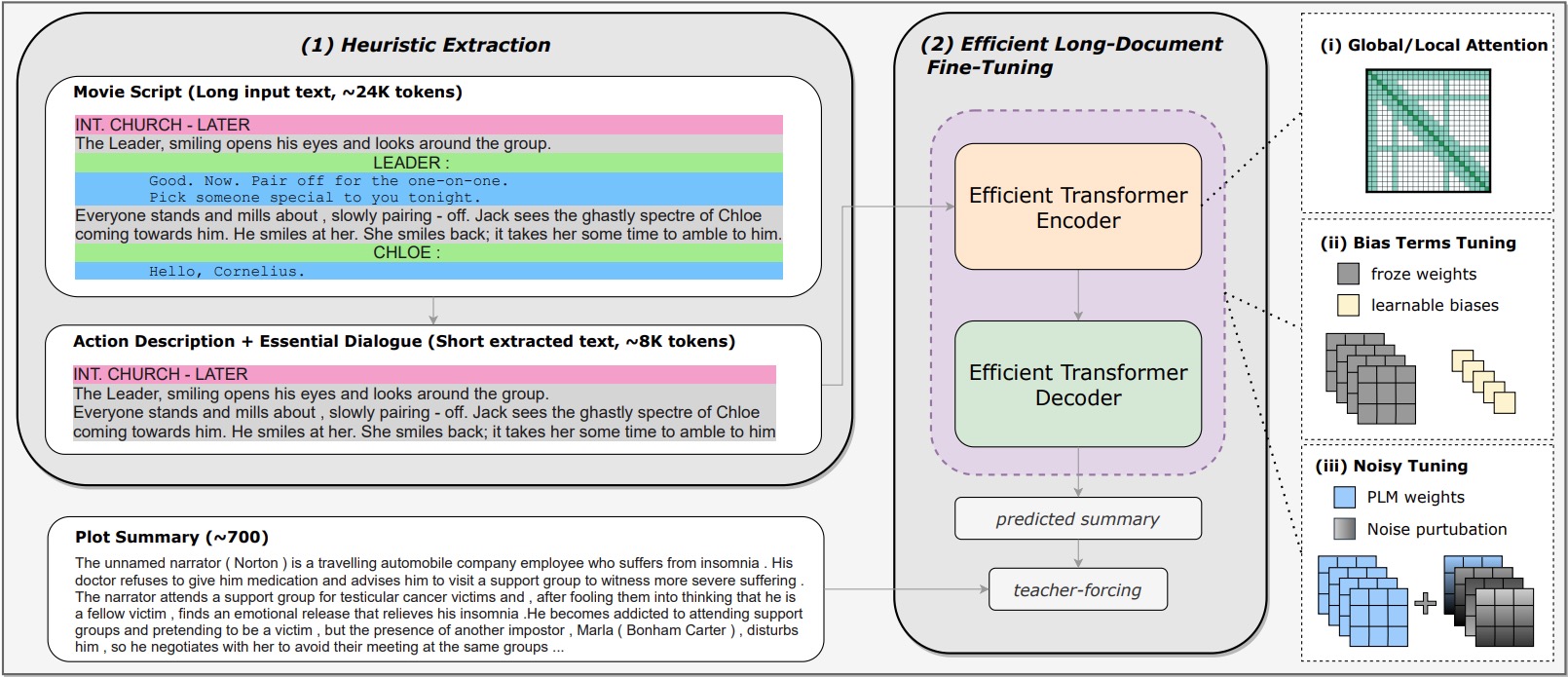
Dongqi Pu*, Xudong Hong*, Pin-Jie Lin*, Ernie Chang, Vera Demberg
COLING 2022
[Paper]
Achieving top performance in movie script summarization.